Lecture 7#
1 Policy Learning#
状态 s t s_{t} s t o t o_{t} o t a t a_{t} a t r t r_{t} r t π ( a t ∣ s t ) , π ( a t ∣ o t ) \pi(a_{t}|s_{t}),\pi(a_{t}|o_{t}) π ( a t ∣ s t ) , π ( a t ∣ o t ) s t = o t s_{t}=o_{t} s t = o t
通常有两种学习模式:
可监督:对于任意状态 s t s_{t} s t a t ∗ a_{t}^{*} a t ∗ L = − ∑ t log π ( a t ∗ ∣ s t ) \mathcal{L}=-\sum_{t}\log \pi(a_{t}^{*}|s_{t}) L = − ∑ t log π ( a t ∗ ∣ s t )
强化学习:对于任意状态 s t s_{t} s t a t ∗ a_{t}^{*} a t ∗ L = − ∑ t r t \mathcal{L}=-\sum_{t}r_{t} L = − ∑ t r t
2 模仿学习#
world model:给出世界发展的动力学 p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_{t},a_{t}) p ( s t + 1 ∣ s t , a t ) I t I_{t} I t p ( I t + 1 ∣ I t , t e x t ) p(I_{t+1}|I_{t},text) p ( I t + 1 ∣ I t , t e x t )
Dagger:Dataset Aggregation(借助人类标注)
train π θ ( a t ∣ o t ) \pi_{\theta}(a_{t}|o_{t}) π θ ( a t ∣ o t ) D = o 1 , a 1 , . . . , o N , a N D = {o_{1}, a_{1},..., o_{N}, a_{N}} D = o 1 , a 1 , ... , o N , a N
run π θ ( a t ∣ o t ) \pi_{\theta}(a_{t}|o_{t}) π θ ( a t ∣ o t ) D π = o 1 , . . , o m D_{\pi} = {o_{1},.., o_{m}} D π = o 1 , .. , o m
Ask human to label D π D_{\pi} D π a t a_{t} a t
Aggregate: D = D ∪ D π D=D \cup D_{\pi} D = D ∪ D π
goto 1 for loop
对于当前的人形机器人,Dagger 不是直接获得 label,而是人接管,即 HG-DAgger,当策略出错的时候,人纠正,并且记录下这个状态和动作,之后再用这些数据来训练模型。这样可以提高数据效率。
其它最优 actions 来源:
来自最优策略,比如 3d 场景下的路径可以从 2 D 路径中获得
On policy diagram:随着训练的进行,策略会不断更新,数据分布也会不断变化,所以需要不断地从新的策略中采样数据来训练模型
Off policy diagram:策略更新的时候,数据分布并不发生改变,可能会出现重复修正、训练低效的问题。
从 teacher policy 学习,student 提供 o t o_{t} o t π T , t \pi_{T,t} π T , t π t ≈ π T , t \pi_{t}\approx\pi_{T,t} π t ≈ π T , t
Non-Markovian 问题:运用历史信息不一定会让策略更好,因为很容易会出现过拟合
对专家拟合失败的原因
多峰问题:对于一个问题的答案不一定是 Gaussian 的,而有可能是多峰的,要解决这个问题要么离散化,要么使用类似 diffusion 的 model,或者加入隐变量
Lecture 8#
1 强化学习#
MDP (Markov Decision Process):M = ( S , A , T , r ) \mathcal{M}=(S,A,\mathcal{T},r) M = ( S , A , T , r ) S S S A A A T \mathcal{T} T r r r T i j k = P ( s t + 1 = i ∣ s t = j , a t = k ) \mathcal{T}_{ijk}=P(s_{t+1}=i|s_{t}=j,a_{t=k}) T ij k = P ( s t + 1 = i ∣ s t = j , a t = k ) o t o_{t} o t s t s_{t} s t M = ( S , A , T , r , O ) \mathcal{M}=(S,A,\mathcal{T},r,O) M = ( S , A , T , r , O ) O O O
强化学习的目标是找到一个 policy π ( a t ∣ s t ) \pi(a_{t}|s_{t}) π ( a t ∣ s t )
θ ⋆ = arg max θ E τ ∼ p θ ( τ ) [ ∑ t = 0 T r ( s t , a t ) ] = arg max θ ∑ i = 1 T E ( s t , a t ) ∼ p θ ( s t , a t ) [ r ( s t , a t ) ] \begin{align}
\theta^{\star} & = \arg\max_{\theta} \mathbb{E}_{\tau\sim p_{\theta}(\tau)}\left[\sum_{t=0}^{T}r(s_{t},a_{t})\right] \\
& = \arg\max_{\theta} \sum_{i=1}^{T}\mathbb{E}_{(s_{t},a_{t})\sim p_{\theta}(s_{t},a_{t})}\left[r(s_{t},a_{t})\right]
\end{align} θ ⋆ = arg θ max E τ ∼ p θ ( τ ) [ t = 0 ∑ T r ( s t , a t ) ] = arg θ max i = 1 ∑ T E ( s t , a t ) ∼ p θ ( s t , a t ) [ r ( s t , a t ) ] 2 策略梯度#
令 J θ = E τ ∼ p θ ( τ ) r ( τ ) = ∫ p θ ( τ ) r ( τ ) d τ J_{\theta}=\mathbb{E}_{\tau \sim p_{\theta}(\tau)}r(\tau)=\int p_{\theta}(\tau)r(\tau)\mathrm{d}\tau J θ = E τ ∼ p θ ( τ ) r ( τ ) = ∫ p θ ( τ ) r ( τ ) d τ
∇ θ J θ = ∫ ∇ θ p θ ( τ ) r ( τ ) d τ = ∫ p θ ( τ ) ∇ θ log p θ ( τ ) r ( τ ) d τ = E τ ∼ p θ ( τ ) [ ∇ θ log p θ ( τ ) r ( τ ) ] \nabla_{\theta} J_{\theta} = \int \nabla_{\theta} p_{\theta}(\tau) r(\tau) \mathrm{d}\tau = \int p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) r(\tau) \mathrm{d}\tau = \mathbb{E}_{\tau \sim p_{\theta}(\tau)}\left[\nabla_{\theta} \log p_{\theta}(\tau) r(\tau)\right] ∇ θ J θ = ∫ ∇ θ p θ ( τ ) r ( τ ) d τ = ∫ p θ ( τ ) ∇ θ log p θ ( τ ) r ( τ ) d τ = E τ ∼ p θ ( τ ) [ ∇ θ log p θ ( τ ) r ( τ ) ] 又根据 log p θ ( τ ) = log p ( s 1 ) + ∑ t = 1 T ( log π θ ( a t ∣ s t ) + log p ( s T ∣ a T , s T ) ) \log p_{\theta}(\tau)=\log p (s_1) + \sum_{t=1}^{T}\left(\log \pi_{\theta}(a_{t}|s_{t}) + \log p(s_{T}|a_{T},s_{T})\right) log p θ ( τ ) = log p ( s 1 ) + ∑ t = 1 T ( log π θ ( a t ∣ s t ) + log p ( s T ∣ a T , s T ) )
∇ θ J θ = E τ ∼ p θ ( τ ) [ ∑ t = 1 T ∇ θ log π θ ( a t ∣ s t ) ∑ t = 1 T r ( s t , a t ) ] \nabla _{\theta} J_{\theta} = \mathbb{E}_{\tau \sim p_{\theta}(\tau)}\left[\sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}(a_{t}|s_{t}) \sum_{t=1}^{T}r(s_{t},a_{t})\right] ∇ θ J θ = E τ ∼ p θ ( τ ) [ t = 1 ∑ T ∇ θ log π θ ( a t ∣ s t ) t = 1 ∑ T r ( s t , a t ) ] Monte Carlo 模拟:
E τ ∼ p θ ( τ ) [ ∑ t r ( s t , a t ) ] ≈ 1 N ∑ i ∑ t r ( s i , t , a i , t ) E_{\tau\sim p_{\theta}(\tau)}\left[\sum_{t}r(\mathbf{s}_{t},\mathbf{a}_{t})\right]\approx\frac{1}{N}\sum_{i}\sum_{t}r(\mathbf{s}_{i,t},\mathbf{a}_{i,t}) E τ ∼ p θ ( τ ) [ t ∑ r ( s t , a t ) ] ≈ N 1 i ∑ t ∑ r ( s i , t , a i , t ) 另外,梯度也使用
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ( ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ) ( ∑ t = 1 T r ( s i , t , a i , t ) ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \left( \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}(\mathbf{a}_{i,t} | \mathbf{s}_{i,t}) \right) \left( \sum_{t=1}^{T} r(\mathbf{s}_{i,t}, \mathbf{a}_{i,t}) \right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N ( t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ) ( t = 1 ∑ T r ( s i , t , a i , t ) ) REINFORCE algorithm:
sample { τ i } \{\tau^{i}\} { τ i } π θ ( a t ∣ s t ) \pi_{\theta}\left(\mathbf{a}_{t} \mid \mathbf{s}_{t}\right) π θ ( a t ∣ s t )
∇ θ J ( θ ) ≈ ∑ i ( ∑ t ∇ θ log π θ ( a t i ∣ s t i ) ) ( ∑ t r ( s t i , a t i ) ) \nabla_{\theta} J(\theta) \approx \sum_{i}\left(\sum_{t} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{t}^{i} \mid \mathbf{s}_{t}^{i}\right)\right)\left(\sum_{t} r\left(\mathbf{s}_{t}^{i}, \mathbf{a}_{t}^{i}\right)\right) ∇ θ J ( θ ) ≈ ∑ i ( ∑ t ∇ θ log π θ ( a t i ∣ s t i ) ) ( ∑ t r ( s t i , a t i ) ) θ ← θ + α ∇ θ J ( θ ) \theta \leftarrow \theta + \alpha \nabla_{\theta} J(\theta) θ ← θ + α ∇ θ J ( θ )
但是这通常十分昂贵,因为每次采样的数据都不能复用,这也被称为 on policy RL,与之相对的,off policy RL 允许复用一段时间前的数据
on policy 一般只能在 simulator 里面搞,现实数据太昂贵搞不了
[!note] 一个值得注意的区分
这里的梯度长得很像 behavior cloning 那里的 Maximum Likelihood 梯度
∇ θ J M L ( θ ) ≈ 1 N ∑ i = 1 N ( ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ) \nabla_{\theta} J_{ML}(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \left( \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}(\mathbf{a}_{i,t} | \mathbf{s}_{i,t}) \right) ∇ θ J M L ( θ ) ≈ N 1 i = 1 ∑ N ( t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ) 但是这完全是两种东西,因为后者的 a t a_{t} a t
事实上,如果 a t a_{t} a t
E τ ∼ p θ ( τ ) [ ∇ θ log π θ ( a i , t ∣ s i , t ) ] = 0 E_{\tau \sim p_{\theta}(\tau)}\left[\nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\right]=0 E τ ∼ p θ ( τ ) [ ∇ θ log π θ ( a i , t ∣ s i , t ) ] = 0 但是如果是 behavior cloning 的结果,那么有
∇ θ J M L ( θ ) = E τ ∼ π expert ( τ ) [ ∇ θ log π θ ( a i , t ∣ s i , t ) ] ≠ 0 \nabla_{\theta} J_{\mathrm{ML}}(\theta)=\mathbb{E}_{\tau \sim \pi_{\text {expert }}(\tau)}\left[\nabla_{\theta} \log \pi_{\theta}\left(a_{i, t} \mid s_{i, t}\right)\right] \neq 0 ∇ θ J ML ( θ ) = E τ ∼ π expert ( τ ) [ ∇ θ log π θ ( a i , t ∣ s i , t ) ] = 0 2.1 高斯策略#
策略服从高斯分布: π θ ( a t ∣ s t ) = N ( f neural network ( s t ) ; Σ ) \pi_{\theta}\left(\mathbf{a}_{t} \mid \mathbf{s}_{t}\right)=\mathcal{N}\left(f_{\text {neural network }}\left(\mathbf{s}_{t}\right) ; \Sigma\right) π θ ( a t ∣ s t ) = N ( f neural network ( s t ) ; Σ ) log π θ ( a t ∣ s t ) = − 1 2 ∥ f ( s t ) − a t ∥ Σ 2 + const \log \pi_{\theta}\left(\mathbf{a}_{t} \mid \mathbf{s}_{t}\right)=-\frac{1}{2}\left\|\boldsymbol{f}\left(\mathbf{s}_{t}\right)-\mathbf{a}_{t}\right\|_{\Sigma}^{2}+\text { const } log π θ ( a t ∣ s t ) = − 2 1 ∥ f ( s t ) − a t ∥ Σ 2 + const ∇ θ log π θ ( a t ∣ s t ) = − ( d f d θ ) T Σ − 1 ( f ( s t ) − a t ) \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right)=-\left(\frac{d f}{d \theta}\right)^{T} \Sigma^{-1}\left(f\left(s_{t}\right)-a_{t}\right) ∇ θ log π θ ( a t ∣ s t ) = − ( d θ df ) T Σ − 1 ( f ( s t ) − a t )
2.2 Partial Observability#
直接用 o t o_{t} o t s t s_{t} s t
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ( ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ o i , t ) ) ( ∑ t = 1 T r ( s i , t , a i , t ) ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N}\left(\sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{o}_{i, t}\right)\right)\left(\sum_{t=1}^{T} r\left(\mathbf{s}_{i, t}, \mathbf{a}_{i, t}\right)\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N ( t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ o i , t ) ) ( t = 1 ∑ T r ( s i , t , a i , t ) ) 3 降低方差#
对于强化学习而言,梯度存在很大不确定性,降低方差可以让算法更快地收敛
第一个办法是只保留 reward to go,也即只考虑 t ′ ≥ t t'\geq t t ′ ≥ t
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N [ ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ( ∑ t ′ = t T r ( s i , t ′ , a i , t ′ ) ) ] \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N}\left[\sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(\sum_{t'=t}^{T} r\left(\mathbf{s}_{i, t'}, \mathbf{a}_{i, t'}\right)\right)\right] ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N [ t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ( t ′ = t ∑ T r ( s i , t ′ , a i , t ′ ) ) ] 第二个办法是减去一个常数 baseline
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∇ θ log p θ ( τ ) [ r ( τ ) − b ] \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \nabla_{\theta} \log p_{\theta}(\tau)[r(\tau)-b] ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N ∇ θ log p θ ( τ ) [ r ( τ ) − b ] 可以证明,最优的 b b b
b = E g 2 ( τ ) r ( τ ) E g 2 ( τ ) , g ( τ ) = ∇ θ log p θ ( τ ) b = \dfrac{\mathbb{E}g^{2}(\tau)r(\tau)}{\mathbb{E}g^{2}(\tau)} ,\quad g(\tau) = \nabla_{\theta} \log p_{\theta}(\tau) b = E g 2 ( τ ) E g 2 ( τ ) r ( τ ) , g ( τ ) = ∇ θ log p θ ( τ ) 但是无法得到,所以通常我们会把 b b b b = 1 N ∑ i = 1 N r ( τ ) b=\frac{1}{N} \sum_{i=1}^{N} r(\tau) b = N 1 ∑ i = 1 N r ( τ )
[!tip]
强化学习算法常常训不出好的 policy,因为 reward 的设计,或者采样太过稀疏,gradient 太 noisy。
4 On-Policy Actor Critic Algorithm#
Q function 和 Value function
Q π ( s t , a t ) = ∑ t ′ = t T E π θ [ r ( s t ′ , a t ′ ) ∣ s t , a t ] : Q^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)=\sum_{t^{\prime}=t}^{T} E_{\pi_{\theta}}\left[r\left(\mathbf{s}_{t^{\prime}}, \mathbf{a}_{t^{\prime}}\right) \mid \mathbf{s}_{t}, \mathbf{a}_{t}\right]: Q π ( s t , a t ) = ∑ t ′ = t T E π θ [ r ( s t ′ , a t ′ ) ∣ s t , a t ] : a t \mathbf{a}_{t} a t s t \mathbf{s}_{t} s t V π ( s t ) = ∑ t ′ = t T E π θ [ r ( s t ′ , a t ′ ) ∣ s t ] : V^{\pi}\left(\mathbf{s}_{t}\right)=\sum_{t^{\prime}=t}^{T} E_{\pi_{\theta}}\left[r\left(\mathbf{s}_{t^{\prime}}, \mathbf{a}_{t^{\prime}}\right) \mid \mathbf{s}_{t}\right]: V π ( s t ) = ∑ t ′ = t T E π θ [ r ( s t ′ , a t ′ ) ∣ s t ] : s t \mathbf{s}_{t} s t
如果能学到很好的 Q 和 V,那么第三种降低方差的方式是使用
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ( Q ( s i , t , a i , t ) − V ( s i , t ) ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(Q\left(\mathbf{s}_{i, t}, \mathbf{a}_{i, t}\right)-V\left(\mathbf{s}_{i, t}\right)\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ( Q ( s i , t , a i , t ) − V ( s i , t ) ) 通常我们会定义 A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t ) A^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)=Q^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)-V^{\pi}\left(\mathbf{s}_{t}\right) A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t ) s t \mathbf{s}_{t} s t a t \mathbf{a}_{t} a t
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) A π ( s i , t , a i , t ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right) A^{\pi}\left(\mathbf{s}_{i, t}, \mathbf{a}_{i, t}\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) A π ( s i , t , a i , t ) 我们通常不直接拟合 Q , A Q,A Q , A
A π ( s t , a t ) ≈ r ( s t , a t ) + V π ( s t + 1 ) − V π ( s t ) A^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) \approx r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+V^{\pi}\left(\mathbf{s}_{t+1}\right)-V^{\pi}\left(\mathbf{s}_{t}\right) A π ( s t , a t ) ≈ r ( s t , a t ) + V π ( s t + 1 ) − V π ( s t ) 只拟合出 V π V^{\pi} V π
4.1 如何拟合 Value Function#
传统办法:直接用 V π ( s t ) ≈ 1 N ∑ i = 1 N ∑ t ′ = t T r ( s t ′ , a t ′ ) V^{\pi}\left(\mathbf{s}_{t}\right) \approx\frac{ 1}{N}\sum_{i=1}^{N}\sum_{t'=t}^{T} r\left(\mathbf{s}_{t'}, \mathbf{a}_{t'}\right) V π ( s t ) ≈ N 1 ∑ i = 1 N ∑ t ′ = t T r ( s t ′ , a t ′ )
Monte Carlo 模拟:直接用 V π ( s t ) ≈ ∑ t ′ = t T r ( s t ′ , a t ′ ) V^{\pi}\left(\mathbf{s}_{t}\right) \approx \sum_{t'=t}^{T} r\left(\mathbf{s}_{t'}, \mathbf{a}_{t'}\right) V π ( s t ) ≈ ∑ t ′ = t T r ( s t ′ , a t ′ )
bootstrap:用 V π ( s t ) ≈ r ( s t , a t ) + V ^ ϕ π ( s t + 1 ) V^{\pi}\left(\mathbf{s}_{t}\right) \approx r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\hat{V}^{\pi}_{\phi}\left(\mathbf{s}_{t+1}\right) V π ( s t ) ≈ r ( s t , a t ) + V ^ ϕ π ( s t + 1 )
此时的误差 δ t = y t − V ^ ϕ ( s t ) \delta_{t}=y_{t}-\hat{V}_{\phi}(s_{t}) δ t = y t − V ^ ϕ ( s t ) y t = r ( s t , a t ) + V ^ ϕ π ( s t + 1 ) y_{t}=r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\hat{V}^{\pi}_{\phi}\left(\mathbf{s}_{t+1}\right) y t = r ( s t , a t ) + V ^ ϕ π ( s t + 1 ) δ t \delta_{t} δ t
5 无穷情形(折现因子)#
对于无穷情形,我们需要引入 discount factor γ \gamma γ
J ( θ ) = E τ ∼ p θ ( τ ) [ ∑ t = 0 ∞ γ t r ( s t , a t ) ] J(\theta) = \mathbb{E}_{\tau \sim p_{\theta}(\tau)}\left[\sum_{t=0}^{\infty} \gamma^{t} r(s_{t}, a_{t})\right] J ( θ ) = E τ ∼ p θ ( τ ) [ t = 0 ∑ ∞ γ t r ( s t , a t ) ] 而且
A π ( s t , a t ) ≈ r ( s t , a t ) + γ V π ( s t + 1 ) − V π ( s t ) A^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) \approx r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\gamma V^{\pi}\left(\mathbf{s}_{t+1}\right)-V^{\pi}\left(\mathbf{s}_{t}\right) A π ( s t , a t ) ≈ r ( s t , a t ) + γ V π ( s t + 1 ) − V π ( s t ) 此时 γ \gamma γ 1 1 1 γ \gamma γ 0 0 0
5.1 Generalized Advantage Estimation (GAE)#
首先,对于折现因子的选择,我们通常是使用
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ( ∑ t ′ = t T γ t ′ − t r ( s i , t ′ , a i , t ′ ) ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(\sum_{t^{\prime}=t}^{T} \gamma^{t^{\prime}-t} r\left(\mathbf{s}_{i, t^{\prime}}, \mathbf{a}_{i, t^{\prime}}\right)\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ( t ′ = t ∑ T γ t ′ − t r ( s i , t ′ , a i , t ′ ) ) 而非
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ( ∑ t = 1 T γ t − 1 r ( s i , t ′ , a i , t ′ ) ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(\sum_{t=1}^{T} \gamma^{t-1} r\left(\mathbf{s}_{i, t^{\prime}}, \mathbf{a}_{i, t^{\prime}}\right)\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ( t = 1 ∑ T γ t − 1 r ( s i , t ′ , a i , t ′ ) ) 这是因为我们使用折现因子,是想对相对位置进行折现,而不是绝对时间
另外,我们在使用 bootstrap 和 policy gradient 的时候,其实分别是用到
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ( r ( s i , t , a i , t ) + γ V ^ ϕ π ( s i , t + 1 ) − V ^ ϕ π ( s i , t ) ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(r\left(\mathbf{s}_{i, t}, \mathbf{a}_{i, t}\right)+\gamma \hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{i, t+1}\right)-\hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{i, t}\right)\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ( r ( s i , t , a i , t ) + γ V ^ ϕ π ( s i , t + 1 ) − V ^ ϕ π ( s i , t ) ) with lower variance but probably bias
和
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ( ( ∑ t ′ = t T γ t ′ − t r ( s i , t ′ , a i , t ′ ) ) − b ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(\left(\sum_{t^{\prime}=t}^{T} \gamma^{t^{\prime}-t} r\left(\mathbf{s}_{i, t^{\prime}}, \mathbf{a}_{i, t^{\prime}}\right)\right)-b\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ( ( t ′ = t ∑ T γ t ′ − t r ( s i , t ′ , a i , t ′ ) ) − b ) with high variance but no bias
所以首先我们就可以改进为
∇ θ J ( θ ) ≈ 1 N ∑ i = 1 N ∑ t = 1 T ∇ θ log π θ ( a i , t ∣ s i , t ) ( ( ∑ t ′ = t T γ t ′ − t r ( s i , t ′ , a i , t ′ ) ) − V ^ ϕ π ( s i , t ) ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(\left(\sum_{t^{\prime}=t}^{T} \gamma^{t^{\prime}-t} r\left(\mathbf{s}_{i, t^{\prime}}, \mathbf{a}_{i, t^{\prime}}\right)\right)-\hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{i, t}\right)\right) ∇ θ J ( θ ) ≈ N 1 i = 1 ∑ N t = 1 ∑ T ∇ θ log π θ ( a i , t ∣ s i , t ) ( ( t ′ = t ∑ T γ t ′ − t r ( s i , t ′ , a i , t ′ ) ) − V ^ ϕ π ( s i , t ) ) 其次,我们考虑前两者之间的优缺点,可以通过 N-steps 的方式权衡,即不止考虑一步,而是考虑
G t ( n ) = ∑ t ′ = t t + n − 1 γ t ′ − t r ( s t ′ , a t ′ ) + γ n V ^ ϕ π ( s t + n ) G_t^{(n)}=
\sum_{t'=t}^{t+n-1}
\gamma^{t'-t} r(s_{t'},a_{t'})+
\gamma^n \hat V_\phi^\pi(s_{t+n}) G t ( n ) = t ′ = t ∑ t + n − 1 γ t ′ − t r ( s t ′ , a t ′ ) + γ n V ^ ϕ π ( s t + n ) 换言之,我们综合了两种 Advantage
A ^ C π ( s t , a t ) = r ( s t , a t ) + γ V ^ ϕ π ( s t + 1 ) − V ^ ϕ π ( s t ) A ^ M C π ( s t , a t ) = ∑ t ′ = t ∞ γ t ′ − t r ( s t ′ , a t ′ ) − V ^ ϕ π ( s t ) \begin{aligned} \hat{A}_{C}^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) & =r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)+\gamma \hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{t+1}\right)-\hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{t}\right) \\ \hat{A}_{\mathrm{MC}}^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) & =\sum_{t^{\prime}=t}^{\infty} \gamma^{t^{\prime}-t} r\left(\mathbf{s}_{t^{\prime}}, \mathbf{a}_{t^{\prime}}\right)-\hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{t}\right) \end{aligned} A ^ C π ( s t , a t ) A ^ MC π ( s t , a t ) = r ( s t , a t ) + γ V ^ ϕ π ( s t + 1 ) − V ^ ϕ π ( s t ) = t ′ = t ∑ ∞ γ t ′ − t r ( s t ′ , a t ′ ) − V ^ ϕ π ( s t ) 给出了新的 Advantage
A ^ n π ( s t , a t ) = ∑ t ′ = t t + n γ t ′ − t r ( s t ′ , a t ′ ) − V ^ ϕ π ( s t ) + γ n V ^ ϕ π ( s t + n ) \hat{A}_{n}^{\pi}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)=\sum_{t^{\prime}=t}^{t+n} \gamma^{t^{\prime}-t} r\left(\mathbf{s}_{t^{\prime}}, \mathbf{a}_{t^{\prime}}\right)-\hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{t}\right)+\gamma^{n} \hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{t+n}\right) A ^ n π ( s t , a t ) = t ′ = t ∑ t + n γ t ′ − t r ( s t ′ , a t ′ ) − V ^ ϕ π ( s t ) + γ n V ^ ϕ π ( s t + n ) 但是这个 n n n n n n V ^ ϕ π \hat V_\phi^\pi V ^ ϕ π n n n n n n
A ^ G A E π ( s t , a t ) = ∑ n = 1 ∞ w n A ^ n π ( s t , a t ) \hat A_{\mathrm{GAE}}^\pi(s_t,a_t)
=
\sum_{n=1}^{\infty}
w_n \hat A_n^\pi(s_t,a_t) A ^ GAE π ( s t , a t ) = n = 1 ∑ ∞ w n A ^ n π ( s t , a t ) 其中权重通常按指数衰减选取:
w n ∝ λ n − 1 w_n \propto \lambda^{n-1} w n ∝ λ n − 1 这里 λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ ∈ [ 0 , 1 ]
A ^ G A E π ( s t , a t ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l \hat A_{\mathrm{GAE}}^\pi(s_t,a_t)
=
\sum_{l=0}^{\infty}
(\gamma\lambda)^l \delta_{t+l} A ^ GAE π ( s t , a t ) = l = 0 ∑ ∞ ( γ λ ) l δ t + l 其中
δ t = r ( s t , a t ) + γ V ^ ϕ π ( s t + 1 ) − V ^ ϕ π ( s t ) \delta_t
=
r(s_t,a_t)
+
\gamma \hat V_\phi^\pi(s_{t+1})
-
\hat V_\phi^\pi(s_t) δ t = r ( s t , a t ) + γ V ^ ϕ π ( s t + 1 ) − V ^ ϕ π ( s t ) 是一步 TD error。这个形式说明,GAE 本质上是在累计当前以及未来若干步的 TD error,但越远的 TD error 权重越小。当 λ = 0 \lambda=0 λ = 0 λ \lambda λ 1 1 1 λ ≈ 0.95 \lambda\approx 0.95 λ ≈ 0.95
Lecture 9#
1 policy 的简单修正#
policy 部分的两个核心问题
gradient 很 noisy,variance 很大
一旦维度高了,batch 就得大一点来降低 noisy
on policy 是一个 data sample efficiency 很低的方法
所有 data 用一次就废
所以要 reuse data:off policy RL,将 data 存在 buffer 里面
在 AC 里面用 off policy 的数据的潜在问题
target 不对:y i = r i + γ V ^ ϕ π ( s i ′ ) y_{i}=r_{i}+\gamma \hat{V}_{\phi}^{\pi}(s_{i}') y i = r i + γ V ^ ϕ π ( s i ′ ) μ \mu μ a a a s ′ s' s ′ r ( s , a ) r(s,a) r ( s , a ) V ϕ π ( s ′ ) V_{\phi}^{\pi}(s') V ϕ π ( s ′ )
梯度不对:log π θ ( a i ∣ s i ) \log \pi_{\theta}(a_{i}|s_{i}) log π θ ( a i ∣ s i ) π θ \pi_{\theta} π θ
对于第一个问题:我们需要放弃价值函数,因为这时候的 s ′ s' s ′ Q Q Q
y i = r i + γ Q ^ ϕ π ( s i ′ , a i ′ ) y_{i}= r_i + \gamma \hat{Q}_{\phi}^{\pi}(s'_i, a'_i) y i = r i + γ Q ^ ϕ π ( s i ′ , a i ′ ) 相应地,loss 改为 L ( ϕ ) = 1 N ∑ i ∥ Q ^ ϕ π ( s i , a i ) − y i ∥ 2 \mathcal{L}(\phi) = \frac{1}{N} \sum_{i} \left\| \hat{Q}_{\phi}^{\pi}(s_i, a_i) - y_i \right\|^2 L ( ϕ ) = N 1 ∑ i Q ^ ϕ π ( s i , a i ) − y i 2
对于第二个问题,首先,由于第一个问题的解决方案,我们不再能估计 V π V^{\pi} V π A π A^{\pi} A π s i s_{i} s i a i a_{i} a i
∇ θ J ( θ ) ≈ 1 N ∑ i ∇ θ log π θ ( a i π ∣ s i ) Q ^ ϕ π ( s i , a i π ) \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i} \nabla_{\theta} \log \pi_{\theta}(\mathbf{a}_i^{\pi} | \mathbf{s}_i) \hat{Q}_{\phi}^{\pi}(\mathbf{s}_i, \mathbf{a}_i^{\pi}) ∇ θ J ( θ ) ≈ N 1 i ∑ ∇ θ log π θ ( a i π ∣ s i ) Q ^ ϕ π ( s i , a i π ) 最后结果是
2 TRPO 和 PPO#
PPO 的想法,既然要提升数据 efficiency,那么是否可以简单的数据复用,同一批数据复用 K K K
E x ∼ p ( x ) [ f ( x ) ] = E x ∼ q ( x ) [ p ( x ) q ( x ) f ( x ) ] \mathbb{E}_{x\sim p(x)}[f(x)] = \mathbb{E}_{x\sim q(x)}[ \dfrac{p(x)}{q(x)}f(x)] E x ∼ p ( x ) [ f ( x )] = E x ∼ q ( x ) [ q ( x ) p ( x ) f ( x )] 理论上来说,重要性采样的乘子应该是
p θ ′ ( τ ) p θ ( τ ) = ∏ t = 1 T π θ ′ ( a t ∣ s t ) ∏ t = 1 T π θ ( a t ∣ s t ) \frac{p_{\theta'}(\tau)}{p_{\theta}(\tau)} = \frac{\prod_{t=1}^{T} \pi_{\theta'}(\mathbf{a}_t | \mathbf{s}_t)}{\prod_{t=1}^{T} \pi_{\theta}(\mathbf{a}_t | \mathbf{s}_t)} p θ ( τ ) p θ ′ ( τ ) = ∏ t = 1 T π θ ( a t ∣ s t ) ∏ t = 1 T π θ ′ ( a t ∣ s t ) 但是为了简化,我们做了两件事,第一对于未来奖励,我们考虑 r r r p θ ′ ( τ ) p θ ( τ ) \frac{p_{\theta'}(\tau)}{p_{\theta}(\tau)} p θ ( τ ) p θ ′ ( τ ) π θ ′ ( a t ∣ s t ) π θ ( a t ∣ s t ) \frac{ \pi_{\theta'}(\mathbf{a}_t | \mathbf{s}_t)}{ \pi_{\theta}(\mathbf{a}_t | \mathbf{s}_t)} π θ ( a t ∣ s t ) π θ ′ ( a t ∣ s t )
接下来的问题是,只要这个新策略和旧策略差的比较多,就很容易训崩,未来减小差距,我们的想法是减小 K K K
另一种思路是 PPO,直接控制重要性部分
PPO-Clip:Clip 后保证
∣ π θ ′ ( a t ∣ s t ) π θ ( a t ∣ s t ) − 1 ∣ ≤ ϵ \lvert \frac{ \pi_{\theta'}(\mathbf{a}_t | \mathbf{s}_t)}{ \pi_{\theta}(\mathbf{a}_t | \mathbf{s}_t)}-1 \rvert \le \epsilon ∣ π θ ( a t ∣ s t ) π θ ′ ( a t ∣ s t ) − 1 ∣ ≤ ϵ PPO-penalty:加上惩罚
L K L PEN ( θ ) = E ^ t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t − β KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] L_{KL\text{PEN}}(\theta) = \hat{\mathbb{E}}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t - \beta \text{KL} \left[ \pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t) \right] \right] L K L PEN ( θ ) = E ^ t [ π θ old ( a t ∣ s t ) π θ ( a t ∣ s t ) A ^ t − β KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] d = E ^ t [ KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] d = \hat{\mathbb{E}}_t [\text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)]] d = E ^ t [ KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t )]] β \beta β
If d < d targ / 1.5 d < d_{\text{targ}} / 1.5 d < d targ /1.5 β ← β / 2 \beta \leftarrow \beta / 2 β ← β /2
If d > d targ × 1.5 d > d_{\text{targ}} \times 1.5 d > d targ × 1.5 β ← β × 2 \beta \leftarrow \beta \times 2 β ← β × 2
看起来,在具身的任务中,clip 是最优秀的,
其他注意点,初始化和激活:
正交初始化:高斯采样初始化矩阵,然后 SVD 得到正交的初始化矩阵
使用 Tanh 激活函数
PPO 的经验:首先调好奖励,然后网格搜索参数。PPO 已经是 off policy 领域,最“on policy” 的办法了,虽然很难训,但是已经是最好用的了。
本课程没有提到 Q-learning,和 PPO 的核心区别是,Q-learning 更倾向于学习价值表,一旦动作、状态空间太大了,那么效果不佳;但是 PPO 学习的是策略,会更 robust 一点。Q-learning 的好处在于数据效率高。
Lecture 10#
1 Diffusion Model#
why diffusion?因为无论是估计策略还是估计价值函数,一般都是假设策略满足高斯分布,这天然的是带有单峰分布的假设的,但是真实任务常出现多峰分布。
mixture of gaussian:但是到底多少个多峰分布很难确定,很少用
离散化: RT-2,OpenVLA,但是牺牲了精度,而且无法利用到相邻点之间的相关信息
GAN:现在已经很少用了,他只有对规则分布(如人脸)用的比较好用
Diffusion:现在大家基本用 Diffusion-Based 的算法,甚至是其简化 Flow-matching
2 Flow Matching#
先介绍 Flow Matching 模型
基础假设:z ∼ p noise , x ∼ p data , t ∼ U [ 0 , 1 ] z \sim p_{\text{noise}} , x \sim p_{\text{data}} , t \sim U[0, 1] z ∼ p noise , x ∼ p data , t ∼ U [ 0 , 1 ] x t = ( 1 − t ) x + t z x_t = (1 - t)x + tz x t = ( 1 − t ) x + t z v = z − x v = z - x v = z − x L = ∣ ∣ f θ ( x t , t ) − v ∣ ∣ 2 2 L = ||f_\theta(x_t, t) - v||_2^2 L = ∣∣ f θ ( x t , t ) − v ∣ ∣ 2 2
重建的过程反过来,进行积分,整个过程没有随机性,而且没有条件约束,x , z x,z x , z x x x z z z
conditional flow matching
在训练的时候,对不同的类别,采用不同的 sample 方式,model 加一个参数 v = m o d e l ( x t , y , t ) v= model(x_{t},y,t) v = m o d e l ( x t , y , t ) y y y
如果希望同时学习 unconditional 的模型,可以单独取一个 y y y [ 0 , 0 , ⋯ , 0 ] [0,0,\cdots,0] [ 0 , 0 , ⋯ , 0 ]
然后利用 v = v ϕ + w ( v y − v ϕ ) v = v_{\phi} + w(v_{y}- v_{\phi}) v = v ϕ + w ( v y − v ϕ )
noise schedule:sample 的时候中间步骤的东西比较难学,所以训练时经常会使用 sigmoid 采样,保证中间步骤学到概率更大;当使用时,仍然维持均匀的采样
对于高清晰度的图像修复,噪声阶段会更嘈杂,为了能够在早期学习更充分,往往会采用 log normal 的 schedule
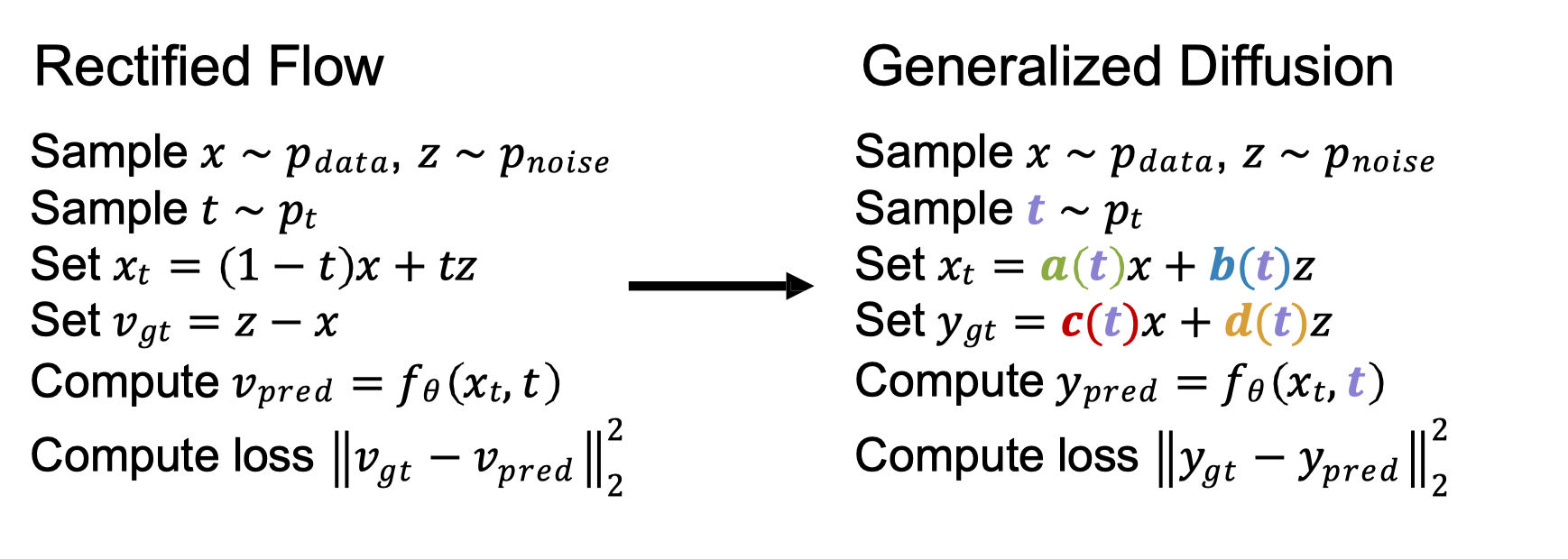
Diffusion 相比 flow matching 的区别:插值不再采用线性插值,而是使用和 t t t
一般对于 diffusion model,我们会选择:
x t = α ˉ t x + 1 − α ˉ t z x_{t}=\sqrt{\bar{\alpha}_{t}}x+\sqrt{1-\bar{\alpha}_{t}}z x t = α ˉ t x + 1 − α ˉ t z 此时可以近似写成随机微分方程
d x = f ( x , t ) d t + g ( t ) d w dx = f(x, t)dt + g(t)dw d x = f ( x , t ) d t + g ( t ) d w 另外, c , d c,d c , d
x-prediction: y g t = x [ c ( t ) = 1 ; d ( t ) = 0 ] y_{gt} = x \quad [c(t) = 1; d(t) = 0] y g t = x [ c ( t ) = 1 ; d ( t ) = 0 ]
ϵ \epsilon ϵ y g t = z [ c ( t ) = 0 ; d ( t ) = 1 ] y_{gt} = z \quad [c(t) = 0; d(t) = 1] y g t = z [ c ( t ) = 0 ; d ( t ) = 1 ] v-prediction: y g t = b ( t ) z − a ( t ) x y_{gt} = b (t) z - a (t) x y g t = b ( t ) z − a ( t ) x
diffusion/flow matching 能 work 的本质原因:因为搞了很多小分布加一起,如果强行蒸馏效果可能不乐观。原则上来说,越复杂的分布,需要越大的步数
diffusion 的关键难题,积分形式下已经写不出来他的显式 p ( x ) p(x) p ( x )
3 Diffusion policy#
如何克服 diffusion 的随机性导致的决策的不连续性?每次预测一批序列,然后成批执行 action chunk
但是这会导致小开环的结果,也就是说一批东西太多了,反应慢
所以现在的改进方法之一是只执行第一个动作,后面的动作用插值的办法影响到后续决策
但是 diffusion 还是太慢了,所以 VLA 现在用 flow matching 的多一点
4 LLM#
LLM 本质也是一个序列生成模型,在 GPT-3 以后,大家发现可以用 RLHF 的办法,用 RL 来解决生成的结果不满意的问题。
但是 reward 仍然是一个大问题,早期的探索是,用人类来标注,具体标注的内容是 preference,是弱 reward,然后用Bradley-Terry model 来设计 reward
p ( τ i ≻ τ j ) = exp ( ∑ t r ψ ( s t ( i ) , a t ( i ) ) ) exp ( ∑ t r ψ ( s t ( i ) , a t ( i ) ) ) + exp ( ∑ t r ψ ( s t ( j ) , a t ( j ) ) ) p(\tau_i \succ \tau_j) = \frac{\exp\left(\sum_t r_{\psi}(s_t^{(i)}, a_t^{(i)})\right)}{\exp\left(\sum_t r_{\psi}(s_t^{(i)}, a_t^{(i)})\right) + \exp\left(\sum_t r_{\psi}(s_t^{(j)}, a_t^{(j)})\right)} p ( τ i ≻ τ j ) = e x p ( ∑ t r ψ ( s t ( i ) , a t ( i ) ) ) + e x p ( ∑ t r ψ ( s t ( j ) , a t ( j ) ) ) e x p ( ∑ t r ψ ( s t ( i ) , a t ( i ) ) ) log p ( τ i ≻ τ j ) = log σ ( r ψ ( τ i ) − r ψ ( τ j ) ) \log p(\tau_i \succ \tau_j) = \log \sigma(r_{\psi}(\tau_i) - r_{\psi}(\tau_j)) log p ( τ i ≻ τ j ) = log σ ( r ψ ( τ i ) − r ψ ( τ j )) ψ ← arg max i , j ∑ log σ ( r ψ ( τ i ) − r ψ ( τ j ) ) \psi \leftarrow \arg \max_{i,j} \sum \log \sigma(r_{\psi}(\tau_i) - r_{\psi}(\tau_j)) ψ ← arg max i , j ∑ log σ ( r ψ ( τ i ) − r ψ ( τ j ))
“Better trajectories are exponentially more likely to be chosen based on their reward”
5 RL for Diffusion Policy#
diffusion model 无法用在 policy 上的一个关键障碍是:模型可以很好的预测动作,但是用一个简洁的形式算出对应动作的概率是很困难的。
p θ ( x 0 = a t ∣ s t ) = ∫ p ( x K ) ∏ k = 1 K p θ ( x k − 1 ∣ x k , s t ) d x 1 : K p_\theta(x_0=a_t \mid s_t) = \int p(x_K) \prod_{k=1}^{K} p_\theta(x_{k-1}\mid x_k,s_t) dx_{1:K} p θ ( x 0 = a t ∣ s t ) = ∫ p ( x K ) k = 1 ∏ K p θ ( x k − 1 ∣ x k , s t ) d x 1 : K 目前的学界思路:
DPPO:对内层的每一个去噪过程都看成一个 RL 的过程,所以一共两次 MDP
FPO:
目前的观点:Diffusion policy 处理 multi modal 的问题确实效果更好一点;而且 Diffusion 在处理 imitation learning 部分的效果也更好一点,但是一旦去 RL,效果就烂了。